
How Sparse is Sign Language Data? - Or, Is 1080p Video Really Just 39 bits Per Second, When Signing?
In which I muse on the dimensionality and Information Density of sign language data, looking at it from a few angles, and guesstimate a signal-to-noise ratio that is very, very small. I estimate an information transfer rate of 40-50 bits per second, and calculate that the resulting signal-to-noise ratio could be incredibly low, somewhere vaguely in the range of 0.00000043.
 (
(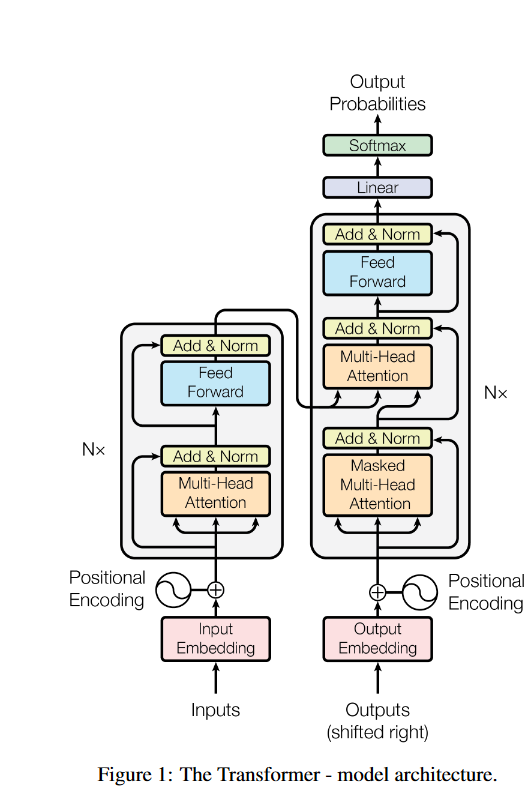 I’ve often wondered, when reading research papers, how exactly it is that people make such pretty figures like this. I decided to look into it, and start collecting resources here.
I’ve often wondered, when reading research papers, how exactly it is that people make such pretty figures like this. I decided to look into it, and start collecting resources here. (
( In the 1990 film Dances with Wolves, Kevin Costner’s character encounters a group of people whose language he does not speak. In order to start establishing a common vocabulary, he uses his body to mime the shape and behavior of a buffalo/bison. Recognizing this, they teach him their word for the animal (“Tatanka”). Our computational approaches to language learning miss out on this kind of thing, relying on massive quantities of mostly text, and leaving much of the data we do have unused. When I’ve spoken with actual linguists working on smaller languages, I’ve found that the they often have data, it’s just not in a form that computers can use easily, distributed across many formats and files. How can we “use the whole Tatanka?”, not wasting the data that is available?
In the 1990 film Dances with Wolves, Kevin Costner’s character encounters a group of people whose language he does not speak. In order to start establishing a common vocabulary, he uses his body to mime the shape and behavior of a buffalo/bison. Recognizing this, they teach him their word for the animal (“Tatanka”). Our computational approaches to language learning miss out on this kind of thing, relying on massive quantities of mostly text, and leaving much of the data we do have unused. When I’ve spoken with actual linguists working on smaller languages, I’ve found that the they often have data, it’s just not in a form that computers can use easily, distributed across many formats and files. How can we “use the whole Tatanka?”, not wasting the data that is available? Summary: Describe the process of creating what is likely the first ever machine translation model for the Hani language, starting with no previous datasets or trained models. Describe data, tools, techniques, and commands used, hopefully enabling easier progress in low-resource translation efforts like this one. Present a baseline and ideas for future improvement.
Summary: Describe the process of creating what is likely the first ever machine translation model for the Hani language, starting with no previous datasets or trained models. Describe data, tools, techniques, and commands used, hopefully enabling easier progress in low-resource translation efforts like this one. Present a baseline and ideas for future improvement. Me, transformed to many 16 different animals
Me, transformed to many 16 different animals