
Hani Neural Machine Translation: Translating A Low Resource Language
- The Goal - Machine Translation for the Hani Language
- Hani Data Inventory
- Creating the Hani Story Corpus
- Training with JoeyNMT
- Results and future work
- Acknowledgements
 Summary: Describe the process of creating what is likely the first ever machine translation model for the Hani language, starting with no previous datasets or trained models. Describe data, tools, techniques, and commands used, hopefully enabling easier progress in low-resource translation efforts like this one. Present a baseline and ideas for future improvement.
Summary: Describe the process of creating what is likely the first ever machine translation model for the Hani language, starting with no previous datasets or trained models. Describe data, tools, techniques, and commands used, hopefully enabling easier progress in low-resource translation efforts like this one. Present a baseline and ideas for future improvement.
The Goal - Machine Translation for the Hani Language
As I have mentioned before, My dream is to translate resources for morality and life into languages which lack them. As a child, I spent some time in the land of the Hani people, where my parents worked as linguists and community development workers. I figured, why not give it a go?
So, towards the end of 2020, I started looking around for data, and I trained the world’s first ever machine translation model for Hani. I briefly describe the process and results below.
Masakhane and the Importance of Concrete Goals
As previously mentioned, I decided to work on a PhD due to my interest in translation.. One of the steps I took to learn more, was to join a online Natural Language Processing (NLP) community known as Masakhane. They face the problem of low-resource NLP on a daily basis, I figured I might learn something! And it turned out to be a wise decision - the people there were kind and helpful.
In particular, Jade Abbot, the founder of Masakhane, said something in a group meeting one day that rather struck me. Remarking on the success and rapid growth of the organization, she mentioned that it was due in large part to having concrete goals - to train baseline translation models for African languages. This helped provide motivation and a clear, achievable target.
Inspired, I decided to do the same for a particular language of my own - Hani!
The Hani Language
Hani is spoken by approximately 1 million people in China and Southeast Asia, depending how you count dialects and groups. By Chinese standards, this makes it a very small minority language! The Hani language is truly low-resource. The complete list of publicly available data in the Hani language that I have been able to find amounts to no more than 3-4 books worth.
Native speakers of Hani, especially in rural areas, have very limited access to information outside of their own tongue. They very few resources in their language, and many don’t speak Mandarin Chinese very well. If a machine translation model could be built for them, perhaps some of the incredible information available in English and other languages could be made accessible to them!
And of course, it is of personal significance to me, as I spent several years of my childhood living in Lüchun.
Hani Data Inventory
The first major step I took was to do an inventory of all Hani data I could find, in particular parallel or translated data.
As expected, there was hardly any available. A few notable sources do exist:
Parallel Data Sources for Hani
UDHR
The Universal Declaration of Human Rights has been translated into over 500 languages… including Hani.
This naturally provides a parallel corpus, as you can simply take the English and Hani versions and align them, e.g. with hunalign or LF Align
However, the corpus is not very large.
It is, however, easily usable in NLP libraries, for example via the NLTK’s “udhr2” corpus, or Hugging Face Datasets. Alternatively they can be simply downloaded directly from the UDHR In Unicode project
51 Hani stories
The largest and best data source I found was “51 Hani Stories”, by Bai Bibo and Paul Lewis, which is available from Amazon here. I managed to get a digital copy from a private source.
A quick note on Bai Bibo: Following the Chinese convention, the surname is written first: Bai. Also, it is apparently the case that his Hani name is Piubo, of which “Bibo” is a Chinese transliteration.
This was the data source I used for my first iteration of the Hani NMT model.
Hani-English, English-Hani dictionary
Also highly helpful has been an electronic copy of the Hani-English, English-Hani dictionary. I managed to pick up a copy on Amazon here. Using the Kindle for PC app, this is fully searchable and very useful for checking individual words. This is also by Paul Lewis and Bai Bibo.
Other Hani Resources
- Wikipedia article
- Omniglot description, with alphabet information, and a few pointers to data sources, including one video!
- Ethnologue entry, contains basic information, mostly blocked behind a paywall.
- Glottolog entry, which also contains a list of “references” which might help.
- OLAC Resources has an interesting list of leads, links to resources, etc. This might be of use for future projects.
- [World Atlas of Linguistic Structures][https://wals.info/languoid/lect/wals_code_han) might be helpful for finding related languages for future transfer learning. Or we could use lang2vec
- Hani Cultural Themes, another book by Bai and Lewis, which might have some useful info.
- Constituent Order and Participant Reference in Dolnia Hani Narrative Discourse is a linguistic Master’s Thesis by SIL researcher Karen Gainer, which also does contain some parallel translations.
- An Crúbadán has some interesting data, such as n-gram frequency counts, which appear to be calculated from the UDHR document.
Creating the Hani Story Corpus
The Hani Story Book was relatively simple to turn into a machine translation corpus, as it already contains parallel translations, with matching paragraph numbers, and story numbers.
For example, see this excerpt:
The basic process I used: First, I managed to get a copy of the 51 Hani Stories book, in electronic (.docx) format.
I then manually copied each of these stories into separate plain text (.txt) files, taking care to do it as cleanly and consistently as possible. For example, I decided that each .txt file would go from before the story number til after the concluding author citation, and tried to do this consistently throughout. This gave me a folderful of 1.txt, 2.txt, 3.txt and so on for each language.
Wrote a simple bash script to concatenate all the 1.txt and 2.txt into hni_stories_concatenated.txt, and en_stories_concatenated.txt.
Aligning the Data with Hunalign
Then, I used the following hunalign command to automatically align the two
hunalign.exe -text -realign -autodict=en_hni_story_corpus_autodict data\null.dic data\en_stories_concatenated.txt data\hni_stories_concatenated.txt > data\en_hni_story_corpus_autoaligned.txt
A note on some of these flags, others are documented on the hunalign repo:
autodicttells it to save the automatic dictionary it generates.- As I didn’t have a Hani dictionary file, for the starter dictionary, I pass it null.dic. In future I’d like to adapt an actual Hani dictionary to see if I get better results.
The output was a single file, with English sentences, Hani sentences, and alignments scores of some description.
I used cut as described in this stackexchange answer to create separate files, as required by JoeyNMT.
This finally gave me 1267 parallel sentences, in two separate files.
Finally, I cut out the first few stories of each, to create a test set. This test set contained story 1, “Waiting for Tomorrow” through the end of story 6, “Alloq Searches for a Cuckoo”, giving me a test set with approximately 10% of the total number of sentences, exactly 120 lines long.
Training with JoeyNMT
For actual training, I used the Custom Data Notebook created by the Masakhane project. It provides relatively straightforward instructions, though I did have to edit the parts dealing with test sets, as my data was not in the JW 300 Corpus it expected. I plan to write a bit more about this in future, and possibly release the notebook as well.
A few quick notes:
- Hani has no special tokenizer in Sacremoses, but default settings appeared to work well, breaking apart words from punctuation.
- Hani also has no tokenization/detokenization support in Sacrebleu.
- Proper calculation of BLEU scores is… difficult to do properly, especially if one cannot detokenize.. At the advice of Mathias Müller on Masakhane, I decided to use chrF instead.
- Other settings mostly were set to default, but I did set validation number to 150, giving me data set sizes of 837 train, 150 dev, and 118 test.
- I added a tensorboard widget, and found that loss curves flattened around 100 epochs.
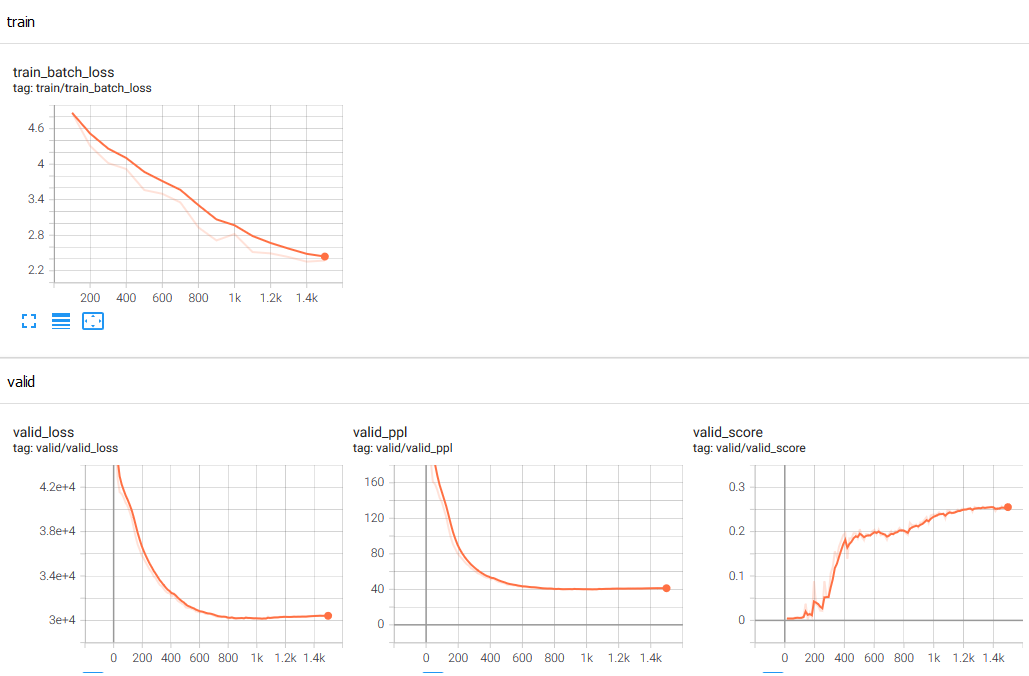
Results and future work
I trained multiple models with different random seeds. The best chrF score I have achieved thus far is the rather low score of 0.24, with most training runs achieving around the same at their peak, plus or minus 0.01 or so. As I am not aware of any other previous attempts to train a machine translation model for the Hani language, this provides both a baseline, and the state of the art.
Manual evaluation reveals that the model does seem to be learning something.
In the following training output sample, we see that at epoch 1 the model outputs (the “hypothesis” line) consist almost entirely of punctuation…
EPOCH 1
Hooray! New best validation result [ppl]!
Saving new checkpoint.
Example #0
Source: 18 . The next year the time of harvest arrived . Aldebo acted as though he was very sorry for Moqsal as he said to him , “ Oh repected elder , respected elder , it is terrible . After the God of heaven had me plant the gold , he told me that I had not told others how to do it . So there has been a terrible drought , and all of the gold plants have withered up . ”
Reference: 18 . Naolhao qiq huvq ceil diq ba ’ la hev al . Aldebo hhoqsaq saq aqmeil zaol duv alnei , Moqsal yaol eil gaq miq : “ Aqbol laoyiq , aqbol laoyiq , maq meeq al . Aoqtav Molmil ngaq yaol siil xa naolhao ssaq deivq lal nia e miqnieiq mol aqqoq yaol eil miq alnei , ngaq yaol eil lal yaq lal . Aoq gee zaol gee alnei , siil dyul saq nei lovq sil saq al . ”
Hypothesis: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
But by epoch 12 it is more reliably outputting words…
EPOCH 12
Hooray! New best validation result [ppl]!
Saving new checkpoint.
Example #0
Source: 18 . The next year the time of harvest arrived . Aldebo acted as though he was very sorry for Moqsal as he said to him , “ Oh repected elder , respected elder , it is terrible . After the God of heaven had me plant the gold , he told me that I had not told others how to do it . So there has been a terrible drought , and all of the gold plants have withered up . ”
Reference: 18 . Naolhao qiq huvq ceil diq ba ’ la hev al . Aldebo hhoqsaq saq aqmeil zaol duv alnei , Moqsal yaol eil gaq miq : “ Aqbol laoyiq , aqbol laoyiq , maq meeq al . Aoqtav Molmil ngaq yaol siil xa naolhao ssaq deivq lal nia e miqnieiq mol aqqoq yaol eil miq alnei , ngaq yaol eil lal yaq lal . Aoq gee zaol gee alnei , siil dyul saq nei lovq sil saq al . ”
Hypothesis: . Aqyoq , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , ,
But then it eventually gets stuck on a particular set of words, outputting them almost every single time:
EPOCH 33
Hooray! New best validation result [ppl]!
Saving new checkpoint.
Example #0
Source: 18 . The next year the time of harvest arrived . Aldebo acted as though he was very sorry for Moqsal as he said to him , “ Oh repected elder , respected elder , it is terrible . After the God of heaven had me plant the gold , he told me that I had not told others how to do it . So there has been a terrible drought , and all of the gold plants have withered up . ”
Reference: 18 . Naolhao qiq huvq ceil diq ba ’ la hev al . Aldebo hhoqsaq saq aqmeil zaol duv alnei , Moqsal yaol eil gaq miq : “ Aqbol laoyiq , aqbol laoyiq , maq meeq al . Aoqtav Molmil ngaq yaol siil xa naolhao ssaq deivq lal nia e miqnieiq mol aqqoq yaol eil miq alnei , ngaq yaol eil lal yaq lal . Aoq gee zaol gee alnei , siil dyul saq nei lovq sil saq al . ”
Hypothesis: 8 . Xil meil qiq nao , “ Nol hal meil nei qiq nao maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao maq ngeel . Nol hal meil leil eil miq . Nol hal meil nei qiq jivq maq hev al . ”
Example #1
Source: 2 . There was a time when frogs and tigers used to play games together . The way they played was not like the way people play . One would try to hide first , and the other would try to set fire to him .
Reference: 2 . Xil meil qiq jol , alhhe haqpaq ssolnei haqlaq ssaqguq hhallul seilhha zaq . Aqyo mavq seilhha e aqqoq mavq aqmeil maq paoq nga . Aqsol huqteil hyuqhheivq alngaoq , aqnu qiq hhaq miqzaq nei bi keq pieiq .
Hypothesis: 8 . Xil meil qiq nao , aqyoq yaol maq hev al . Aqyoq qiq nao , aqyoq yaol maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao maq hev al .
Example #2
Source: 22 . So after that they changed the name of the village from Saolmeil Village , which they originally called it , and called by the new name of Yosaq Puv .
Reference: 22 . Xil jol nei , aqyo mavq miqteil Saolmeil Puv leil kul e puvkaq mol yomiaol miaol siivq , Yosaq Puv leil miaol pal al .
Hypothesis: 8 . Xil meil qiq nao , aqyoq yaol eil miq : “ Nol hal meil qiq nao maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao maq hev al .
Example #3
Source: 10 . The middle daughter could not imagine what to do , so she just led the blind horse and left . Just as dusk was falling she arrived at a place where there was an old , broken down house with a mother and son living there . Every day the mother and son went digging wild yams in ~ ~ ~ order to feed themselves .
Reference: 10 . Miqhhaol qiq jivq nyuq e maq caq . Moq miavbeivq ciil alnei laqnil a maq duv yil maq taq qivq . Daqhhaq hhaol li yul taq luldu , miqhhaol yul meil qiq gal a lal hev . Xil gei laqhyul xaolcyuq qiq yaol jav . Col niq massaq jol . Xil niq massaq taolnao nei moqdev duq alnei , wuqdeiq leiq deiv zaq .
Hypothesis: 8 . Xil meil qiq nao , aqyoq yaol maq hev al . Aqyoq qiq nao , aqyoq yaol maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao nei qiq nao nei qiq nao maq hev al . Aqyoq qiq nao maq hev al . Aqyoq qiq nao , aqyoq yaol maq hev al .
Consultation with a Hani speaker reveals that these are common storytelling phrases, along the lines of “once upon a time”. Searching the original corpus for “Xil meil qiq”, for example, shows 66 hits. Out of only 1267 sentences, this is an appreciable number, and suggests that this small corpus may not be sufficient.
CHRF scores
Following the recommendations of Mathias Müller, I trained multiple times with different different random seeds, and report the mean and standard deviation.
JoeyNMT automatically calculated test scores at the end of training, using the “best” checkpoint. This is defined as the checkpoint with the highest validation score during training. I experimentally determined that an epoch was about 14 training steps long, and so set the validation to occur once every 14 steps. In the following results, epochs can therefore be estimated from steps accordingly.
- seed 42, set to train 300 epochs, best result at step 910: 0.21 on test set.
- seed 43, set to train 300 epochs, best result at step 924: 0.21 on test set.
- seed 44, set to train 150 epochs, best result at step 854: 0.21 on test set.
- seed 45, set to train 100 epochs, best result at step 826: 0.21 on test set.
- seed 46, set to train 100 epochs, best result at step 1036: 0.23 on test set.
- seed 47, set to train 100 epochs, best result at step 868: 0.22 on test set
mean: 0.215, standard deviation: 0.008366600265
Why is it so poor?
Simply put, there’s not enough data.
Future work
- Try again with different hyperparameters?
- Incorporate more data! UDHR for example, would be a useful test set at least, perhaps allowing us to put more back in as training.
- Attempt to incorporate the Hani-English, English-Hani dictionary in some way?
- Perhaps we could analyze the dataset a bit more! My friend Dr. Eric Jackson suggests that maybe there’s not enough lexical coverage and overlap, e.g. the test set might have words that don’t occur in train. What’s the lexical overlap between train/val/test?
- Would different splits work better?
- As a sort of larger-question, is there some way we can analyze the quality of a dataset before running the GPU training? Besides lexical overlap, are there other things we can check? Like, does it cover a good proportion of the morphemes or words in the language? What proportion of the words in the dictionary show up in the set? etc.
Data Augmentation?
It may be possible to use various tricks to augment the dataset. For example, swapping out words in sentences. Rather than “the frog said”, make another version of the sentence with “the cow said”. And so on.
See CS11-737 Multilingual NLP Data-based Strategies to Low-resource MT for more details. Some of the possiblities include:
- Augmenting with back-translation. We have piles of English, Chinese data. Can we create some synthetic Hani?
- Use some of the reordering code from Handling Syntactic Divergence in Low-resource Machine Translation
Acknowledgements
- Jade Abbot for helping me to realize the value of a concrete goal.
- Julia Kreutzer for her work in writing JoeyNMT in the first place, and patient assistance and encouragement in using it properly.
- Mathias Müller for his very helpful post on machine translation evaluation, and advice on how to apply it to this problem!